
Data breaches are in the news daily and organizations spend millions of dollars on damage control for each incident. From a Federal Government standpoint, this concern also includes data spillage – the need to prevent content from getting into the wrong hands.
The concept of data spillage is very different than a hack or data breach. A hack is a malicious attempt to use data. It is a purposeful breach by an unauthorized user with intent to obtain and distribute private information.
Data spillage is typically the result of human error or carelessness. It is an unauthorized movement or disclosure of classified or sensitive information to a party that is not authorized to possess or view the material. This could include:
- Emails
- Mismarked files on servers
- Improperly marked physical records
- Copying of classified documents on an unclassified copier
- An appropriate or lack of assignation of a classification
Typically, an Information Security Officer, or the person who originated the information, is the person responsible for determining the impact of the data spillage. Immediate action includes creation of an incident report and a response to senior leadership on the risk of the spillage.
The risk of the spillage relates to the number of users impacted, the type of data that was spilled, and the importance of the data to an agency’s operations. Spilled data might contain:
- Personally Identifiable Information (PII)
- Intellectual property
- Proprietary data
- Classified military or agency data
Data spillage remediation extends to storage media where the spilled data might migrate to. This means that backups are affected by data spillage. An organization’s backup and recovery methods may actually complicate the remediation process.
Prior to use of cloud environments, a data spillage was corrected through sanitizing the affected hardware to ensure reconstruction of the spilled data was impossible. This process often meant that resources would need to be taken offline to perform the cleanup.
Cloud environments pose a challenging nuance to the remediation process. First, the physical data locations are often difficult to ascertain. Second, loss of availability of a cloud environment that has multiple tenants is just not feasible.
One other consideration is that cloud-based search includes all terms for a source document, thus the search index may get contaminated by data spillage. Cleanup of the index may not be easy and will likely affect availability and performance.
Vana Solutions recently helped a client build their spillage process with the aim that all parties engaged know exactly what needs to be done and by whom. The process was then documented with a flow chart with three “swim lanes” (Impact Analysis, Containment, and Eradication), indicating who is responsible for which steps and in what order these steps were to be executed.
The documented process was then shared widely and communicated clearly so that timely execution may limit the scope and opportunity for further spread of the spill.
Data spillage process includes activities which must be handled in a timely manner by the appropriate people. These activities include:
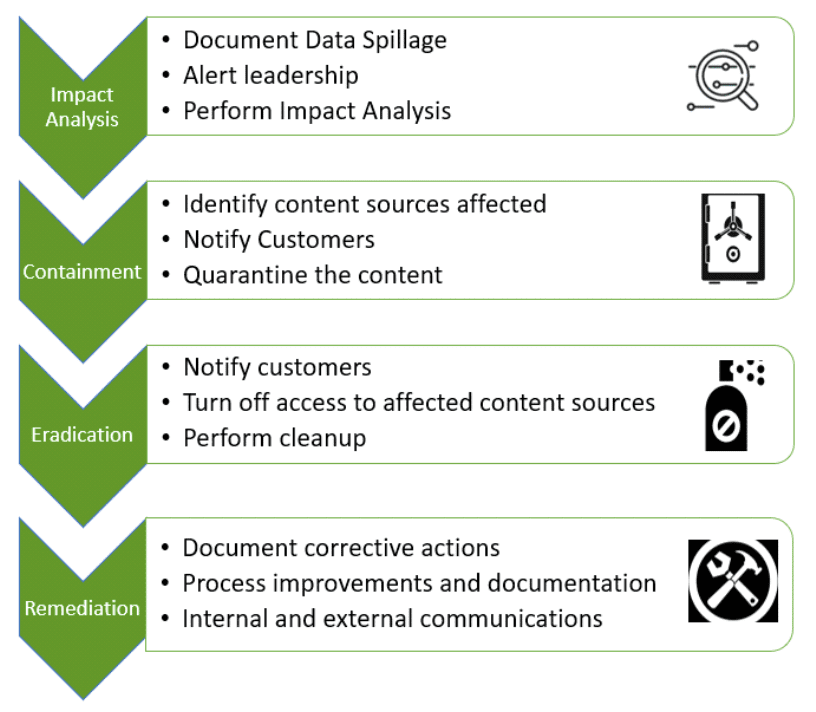
Impact Analysis – Determine who created the spillage, the sensitivity of the data, number of users, and systems/applications involved. The analysis should include both internal and external complications of the data spillage. Since data spillage costs money and possibly a loss of credibility, it is important to create a historical account of the events that led up to the data spillage.
Containment – Identify the hardware, software, and applications affected by the data spoilage. Contain the spill!
Eradication – Use approved sanitization procedures to permanently remove the data spillage from the contaminated systems, applications, and media. Do not forget to cleanup backups. The amount of time that lapsed prior to data spillage detection will help to understand how much backup media may be affected.
Remediation – Determine the source of the spillage and take actions. This includes documenting the corrective action for the data spillage. This documentation is important not just a legal standpoint, but from a training aspect to hopefully prevent the issue in the future. Communication back to internal and external parties is critical for knowledge transfer and process improvement.
Spillage Happens! So, as long as humans are involved in the creation and management of content, the possibility of sharing it with the wrong person or entity exists. Using Enterprise Content Management systems to automate classification and security of content is a best practice which will enforce better controls for content usage.
For more information, the Vana experts are here to help! We bring expertise to your organization in terms of consultation and execution. Contact us today to see how we can help.
